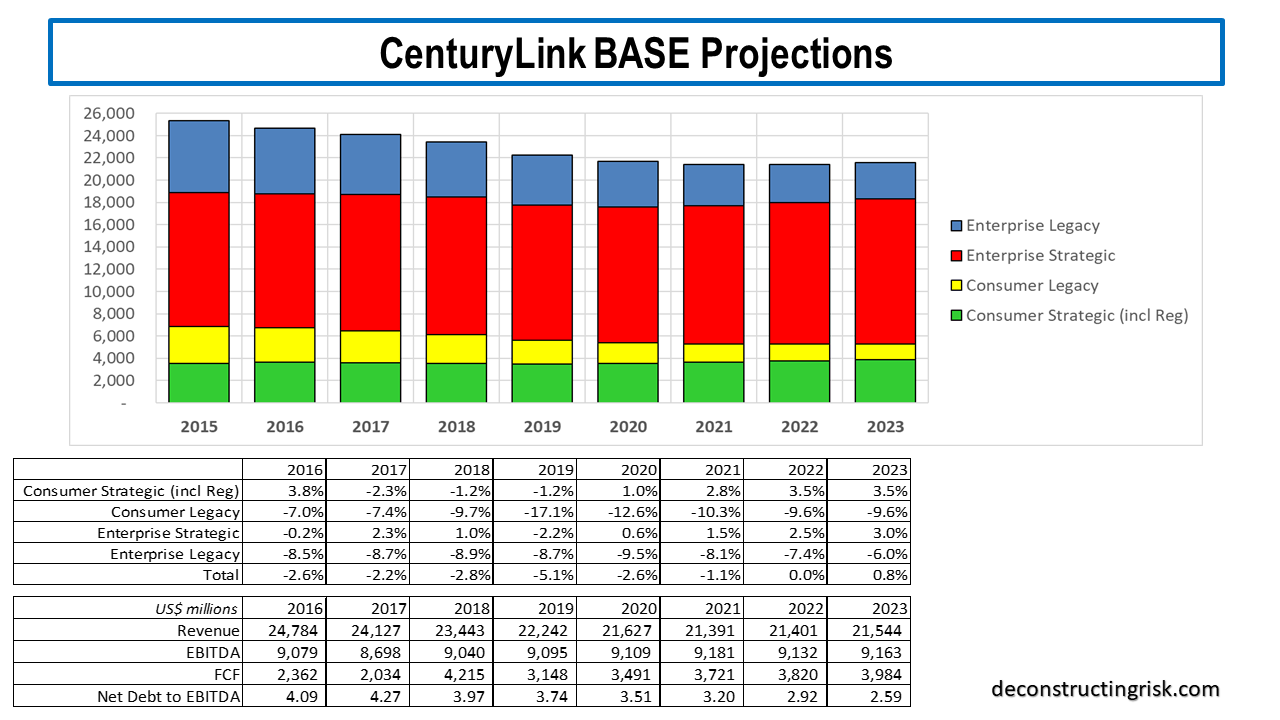
Regular readers will know that I have posted many times on CTL, in particular, and telecom in general (here is the most recent post on CTL). Back in what seems like another world now, I was very much looking forward to the Q4 results in February, specifically the guidance for 2020. I had projected the 2020 results would show a stabilisation of the business and demonstrate the operating leverage in the business model as represented by my EBITDA estimate of at least a $100 million improvement over 2019 and a material slowdown in the revenue yearly erosion.
As it happens, I was very disappointed (a consistent theme with CTL!) by the 2020 projection provided at the year-end results in early February. With an unchanged EBITDA range for 2020 over 2019 of $9 to $9.2 billion, it fell short of my expectations of at least a $100 million improvement on both top and bottom of the range. I yet again found myself having to sharpen my pencil on my CTL projections and given that this a recurring need over the past 2 years, I frustratingly concluded that I needed time to go away and rethink my affection to CTL. I concluded the stock was going nowhere fast and I sold half of my position (which was further reduced as I reduced risk as COVID19 developed) to mull over my thoughts.
Two items in particular bothered me. The first was the statement by the CFO that 25% to 30% of the revenue decline was due to purposeful action undertaken on unprofitable or low profit business. That meant (taking the 30%) that the attritional loss of business in 2019 was, on the old gross of USF basis, approximately $730 million compared to $680 million and $630 million for the two previous years (on an estimated net USF basis, the figures are $620 million, $730 million, and $800 million respectively for 2017 to 2019). Not exactly a decreasing trend!! The second item was the comment about Q1 rerating of contracts for the hyper-scalers. This brought home to me the hold the large tech firms had over the telecom market and how difficult it would be for firms like CTL to ever have pricing power for their services in a commodity like market.
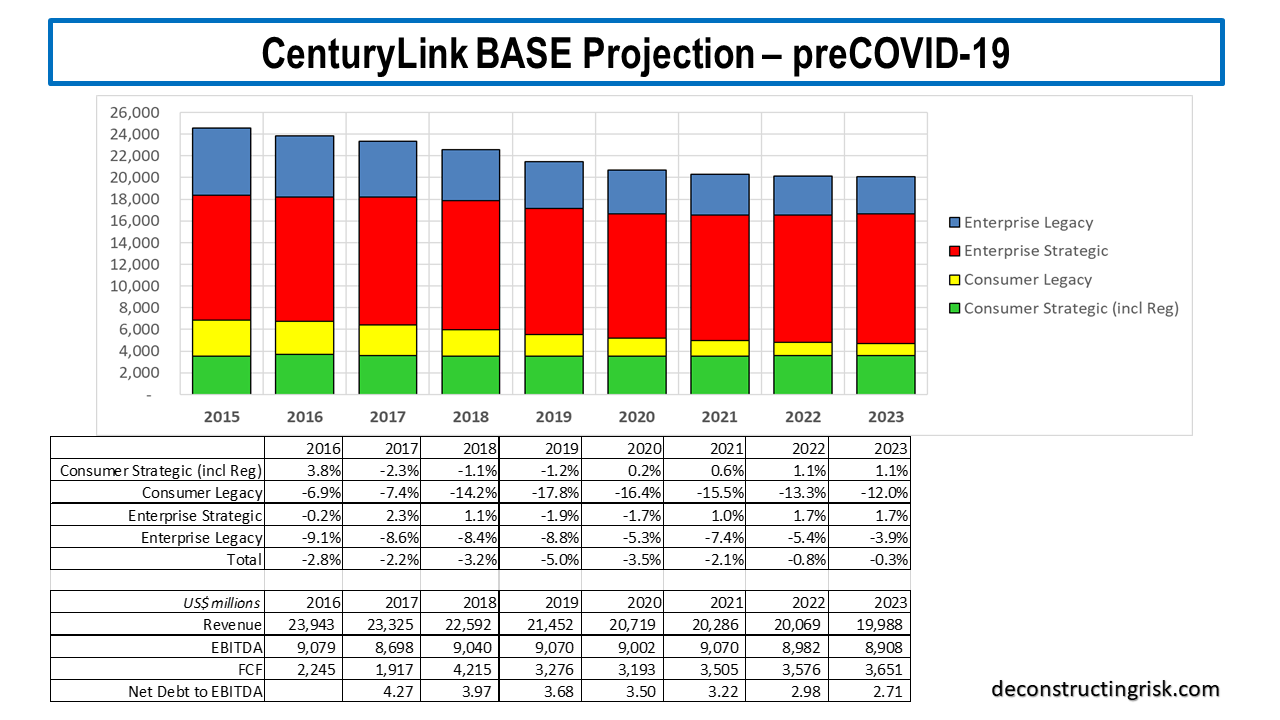
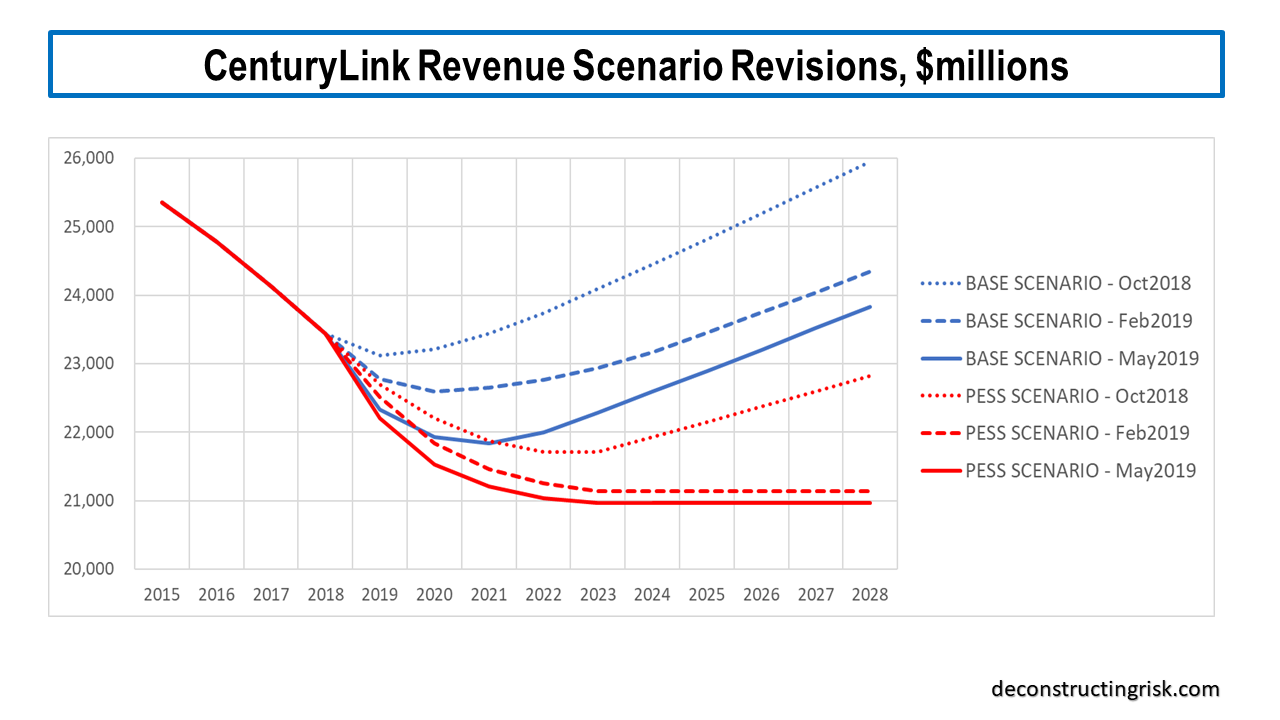
Since that time, CTL made some positive announcements on government EIS contract wins. And of course, the THING happened (more of which later). Just before the Q1 results earlier this month, CTL also announced a change in calculating revenue, to a basis net of USF charges. This is obviously a pain as historical revenue figures (before the quarterly 2019 figures they gave) had to be estimated, based upon the changes in the quarterly USF charges, to get an insight into historical trends. Based upon the revised revenues (net of USF) and giving some credit for new government contracts coming on stream over 2021 and beyond, my revised base projections for CTL, before any COVID19 impact, are below. I did not try to quantify the EIS contracts in dollar terms due to the ambiguities of government contracts; I simply reflected them judgmentally in future percentage changes.
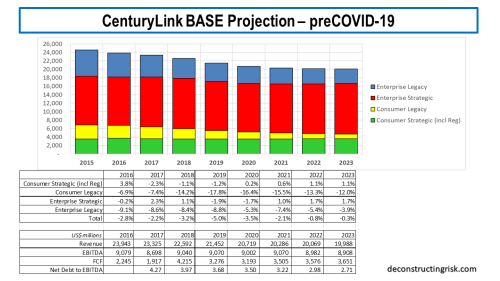
This base projection assumes revenue declines of (on the new net basis) of $730 million, $430 million, $220 million and $80 million for the next 4 years before finally turning to growth in 2023. My discounted cashflow valuation, using an 8% discount rate, for these base projections is $19.60 per share. My previous base case valuations have varied from a high of $28 to a low of $18 per share in recent years.
Due to CTL’s success in areas such as the EIS government contracts, I assumed that the revenue decline will not continue at an annual rate above $700 million indefinitely. As such, my pessimistic projection assumes revenue declines of (on the new net basis) of $780 million, $550 million, $330 million, $190 million, $100 million and $50 million for the next 6 years before finally turning to growth in 2026. These pessimistic projections (with the dividend dropped in H2 2020) resulted in a DCF valuation of $11.80. This is higher than my previous pessimistic valuations of $9-10 per share.
However, these projections are from another era, before COVID19. Assessing the impact of COVID19 on any business is pure speculation currently. Notwithstanding this fact, the COVID19 outbreak has, in my opinion, highlighted the importance of scalable robust networks and the digital transformation of enterprises. Impressively, the whole telecom sector, both wireline and wireless, has generally stepped up admirably during this crisis. Would they have been capable of doing so 10 or even 5 years ago? Additional capacity must be a part of modern networks to facilitate peak demand strains such as a release of a new game like Fortnite or a hot new series streamed on Netflix. The demand for agile and deep fiber networks which can turn quality capacity on and off automatically will become more essential to our way of life and will be recognised as such in the post COVID world. And that should be positive medium term for firms like CTL.
In the Q1 call, management commented that the “acceleration of digital transformation driven by COVID-19 presents a wide range of opportunities for CenturyLink”. [Well, they would, wouldn’t they!] It may just rebalance the pricing dynamics away from the hyper-scalers slightly towards those network providers that can provide adaptable deep low latency scalable networks. Wishful thinking maybe.
In common with many other announcements in Q1, CTL emphasized the uncertainty over the near term when they stated, “we anticipate a negative effect on our near-term results”. They stressed that “we have seen some increased demand, but our business is ultimately only as successful as the businesses of our customers”. They also maintained the dividend (for now anyway) and their debt leverage targets (with a quarter or two delay into 2022). In fact, they were strong on the dividend by stating “we modeled multiple downside scenarios, and under all scenarios, we expect our payout ratio to remain in the 30s as a percentage of free cash flow”. Management identified 5% of total revenue or $1 billion of revenue as being exposed to highly impacted COVID19 businesses (e.g. retail, leisure, restaurants, hotels, airlines). They also did not see any increase in bad debt in Q1 but warned “we do expect to see an increase in bad debt, specifically in our SMB and consumer segments”. They acknowledged “we will have a financial impact in the near term” but that they “have a lot of levers by the time we get to free cash flow” and “we’ll be calibrating our capital to demand and sales”.
So, I made the following changes to my pre-COVID projections:
- Bad debt cashflow write-off of $500 million and $300 million in 2020 and 2021.
- Push out transformation cost savings to be concentrated in 2021 (to reflect, amongst other things, the delay in realising off-net to on-net cost savings due to restricted building access in 2020).
- Reduce capital expenditure in 2020 to 17% of revenues and 17.5% thereafter.
- Push out debt to EBITDA target of below 3.25 one year until 2022.
- Further reduction in revenue, as below, to reflect COVID acceleration in legacy revenue burn-off and firming of new product demand due to acceleration in enterprise’s digital transformation, new governmental EIS contracts, general demand increase with pricing firming for complex reliable network solutions.
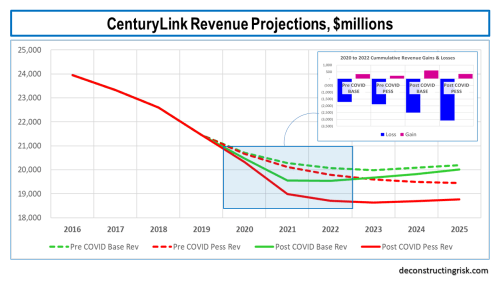
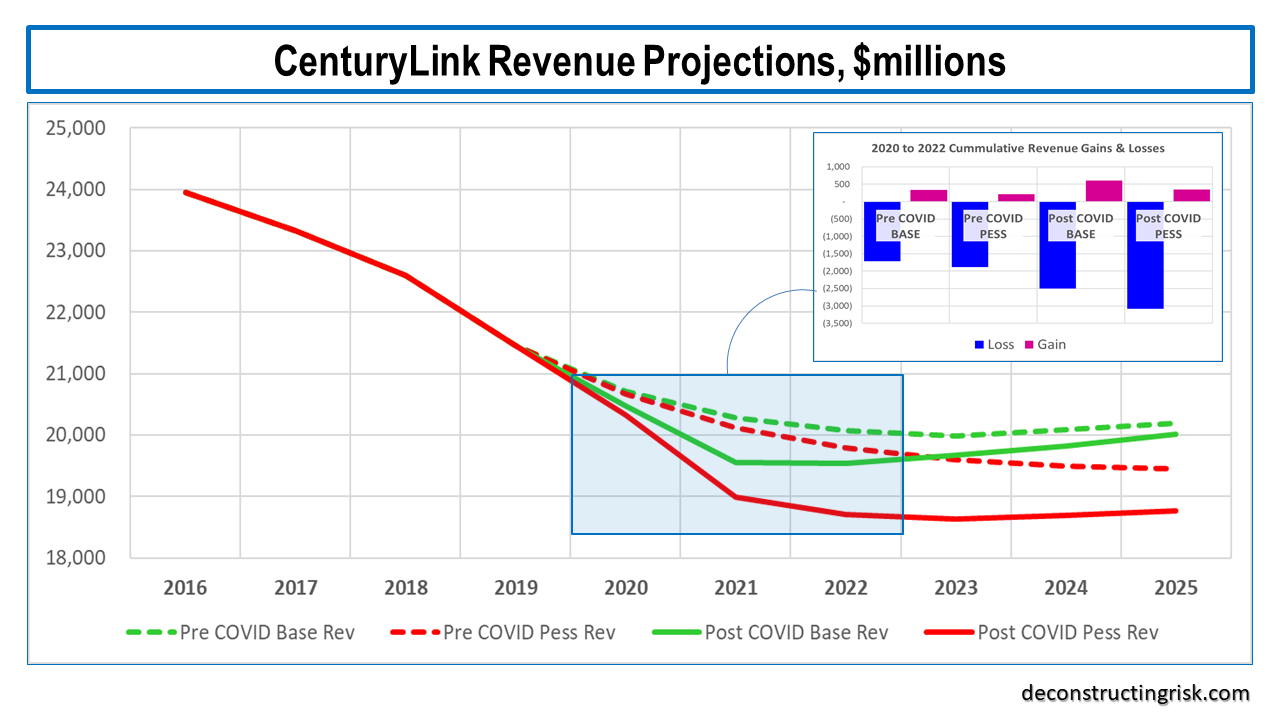
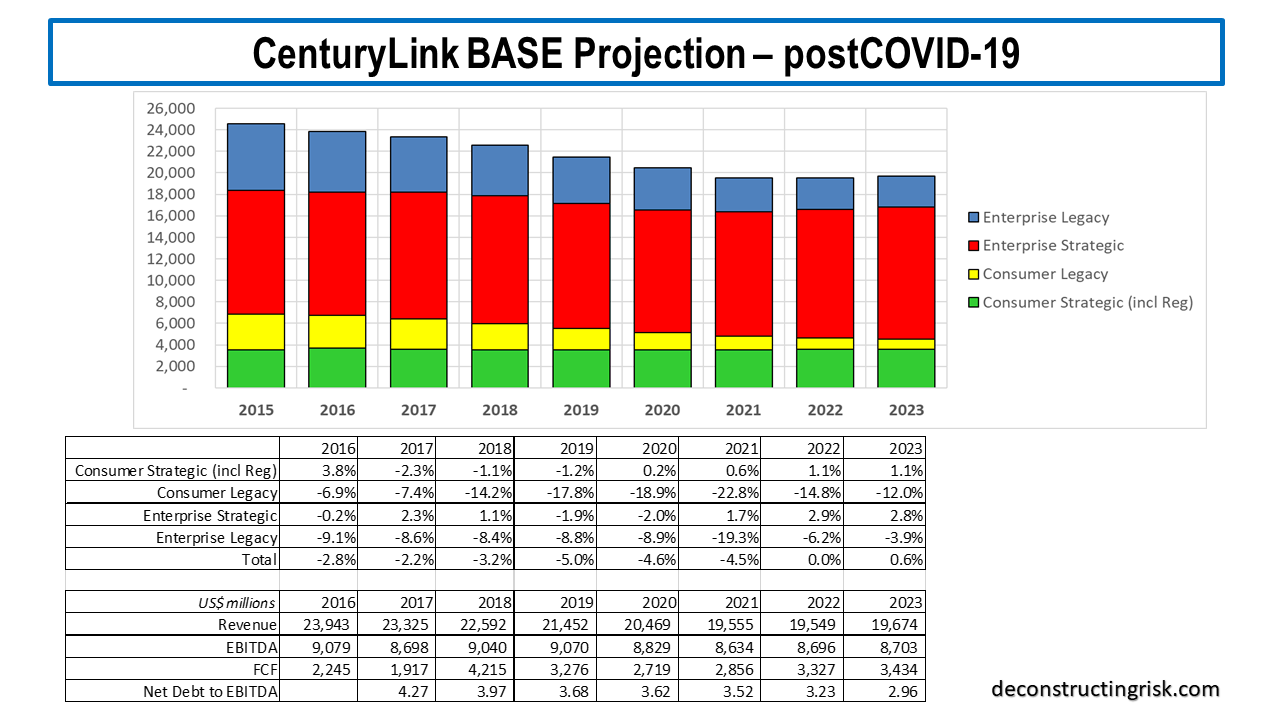
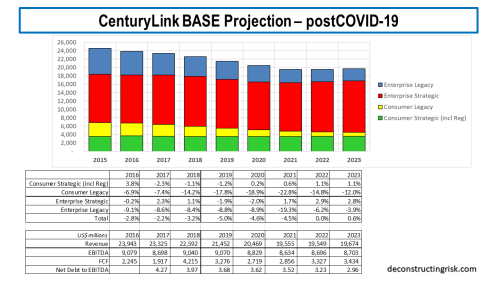
For the 2020 to 2022 years inclusive, I increased the revenue loss from $1.4 billion to $1.9 billion in my base scenario pre-COVID over post-COVID. My revised post-COVID base projection is below.
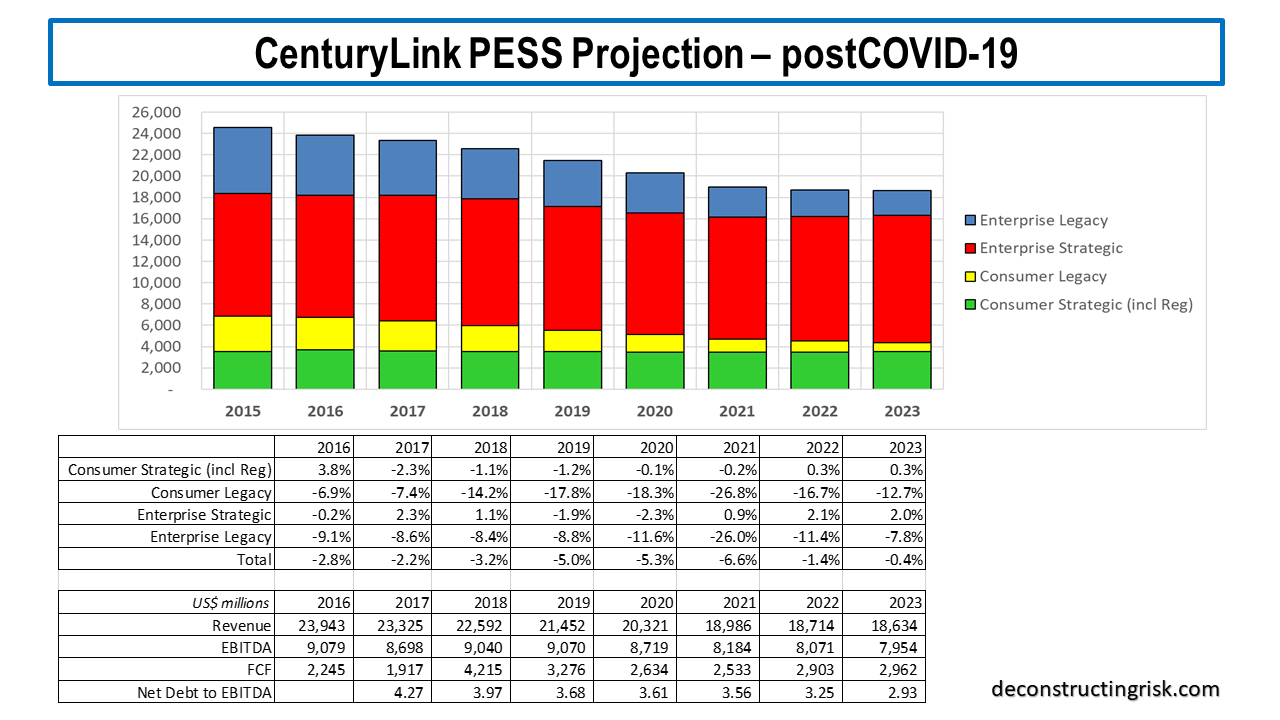
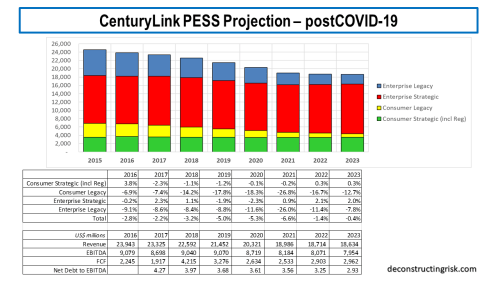
For the pessimistic scenario, the revenue loss over 2020 to 2022 inclusive was from $1.7 billion pre-COVID to $2.7 billion post-COVID. My revised post-COVID pessimistic projection is below.
Based upon these projections, with the same assumptions as outlined in previous posts such as a discount rate of 8% and the elimination of the dividend in H2 2020 in the pessimistic scenario (the dividend is maintained at the same level in the base scenario), my valuation per share is $18.70 and $5.70 in the base and pessimistic case respectively. At the current price of $9.82, that is an approximate 90% upside versus a 40% downside.
Of course, these are just guesstimates at this stage and time will tell how the landscape develops in this topsy turvy COVID world of ours. In a strange way, this pandemic and its aftermath will either prove or disprove the strength of CTL’s network and the robustness of their strategy through an acceleration of their and their client’s digital transformation journey. Something to keep an eye on.