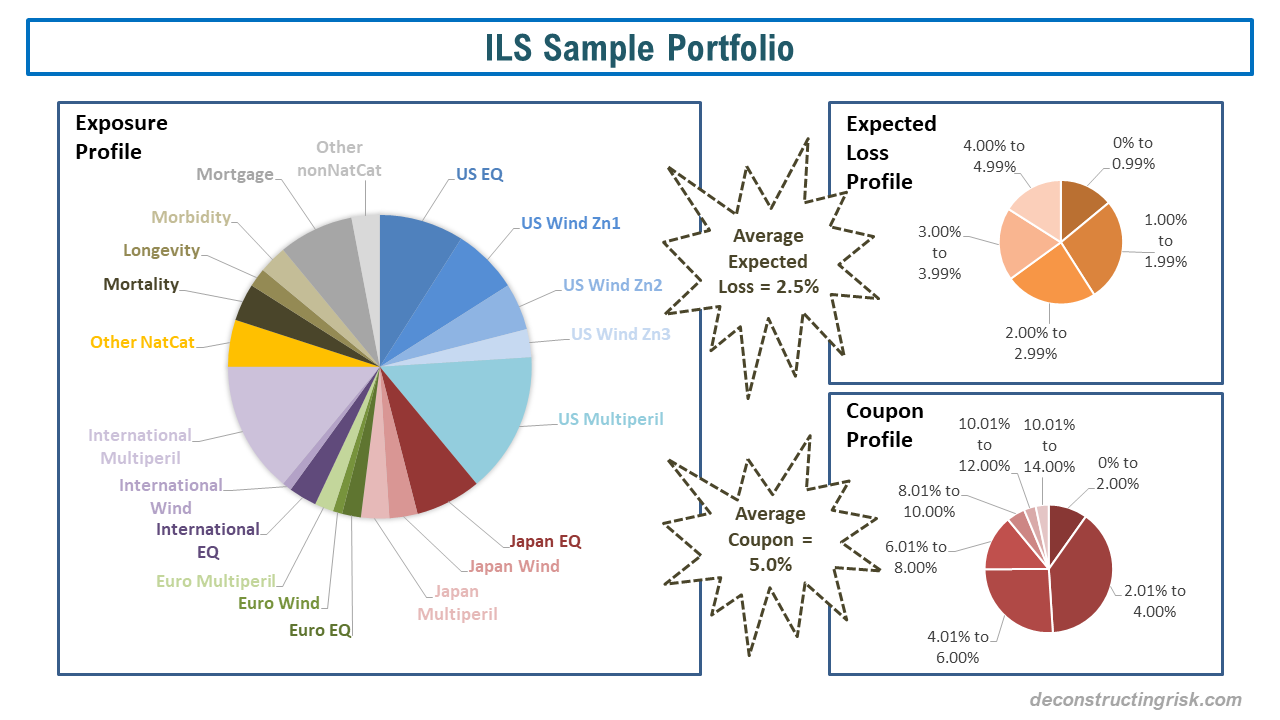
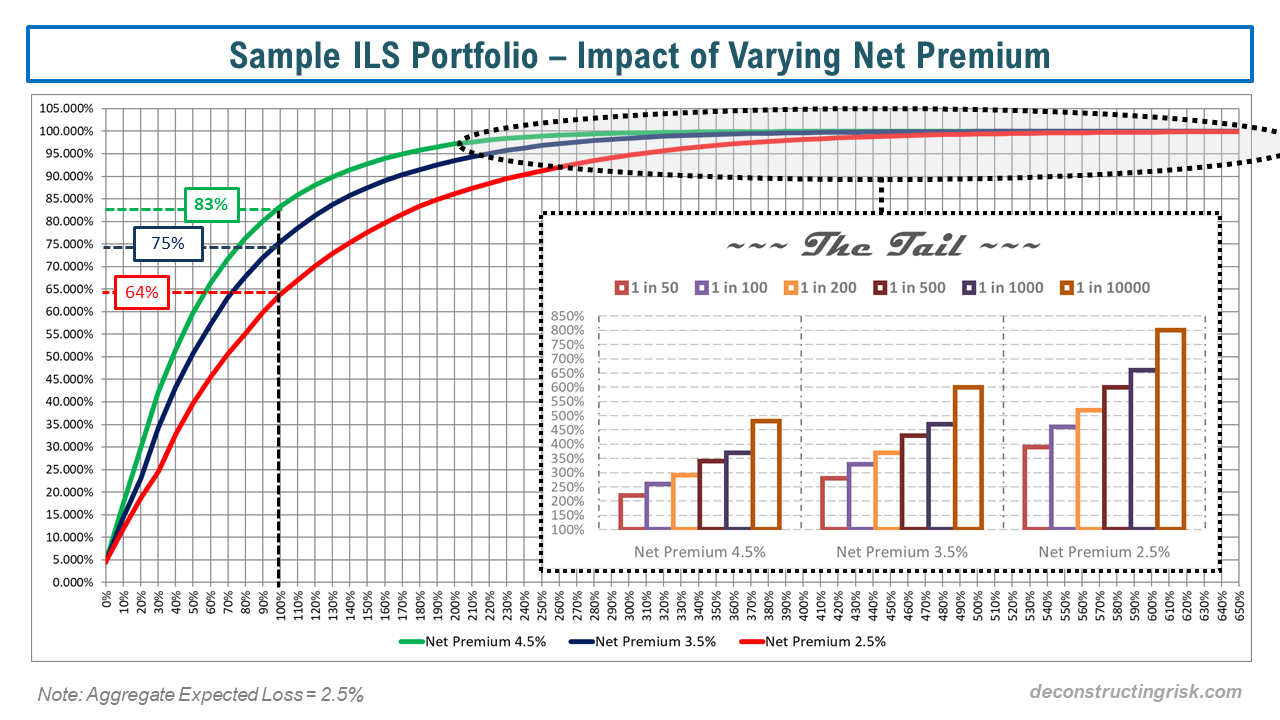
It seems like wherever you look these days there is references to the transformational power of artificial intelligence (AI), including cognitive or machine learning (ML), on businesses and our future. A previous post on AI and insurance referred to some of the changes ongoing in financial services in relation to core business processes and costs. This industry article highlights how machine learning (specifically multi-objective genetic algorithms) can be used in portfolio optimization by (re)insurers. To further my understanding on the topic, I recently bought a copy of a new book called “Advances in Financial Machine Learning” by Marcos Lopez de Prado, although I suspect I will be out of my depth on the technical elements of the book. Other posts on this blog (such as this one) on the telecom sector refer to the impact intelligent networks are having on telecom business models. One example is the efficiencies Centurylink (CTL) have shown in their capital expenditure allocation processes from using AI and this got me thinking about the competitive impact such technology will have on costs across numerous traditional industries.
AI is a complex topic and in its broadest context it covers computer systems that can sense their environment, think, and in some cases learn, and take applicable actions according to their objectives. To illustrate the complexity of the topic, neural networks are a subset of machine learning techniques. Essentially, they are AI systems based on simulating connected “neural units” loosely modelling the way that neurons interact in the brain. Neural networks need large data sets to be “trained” and the number of layers of simulated interconnected neurons, often numbering in their millions, determine how “deep” the learning can be. Before I embarrass myself in demonstrating how little I know about the technicalities of this topic, it’s safe to say AI as referred to in this post encompasses the broadest definition, unless a referenced report or article specifically narrows the definition to a subset of the broader definition and is highlighted as such.
According to IDC (here), “interest and awareness of AI is at a fever pitch” and global spending on AI systems is projected to grow from approximately $20 billion this year to $50 billion in 2021. David Schubmehl of IDC stated that “by 2019, 40% of digital transformation initiatives will use AI services and by 2021, 75% of enterprise applications will use AI”. By the end of this year, retail will be the largest spender on AI, followed by banking, discrete manufacturing, and healthcare. Retail AI use cases include automated customer service agents, expert shopping advisors and product recommendations, and merchandising for omni channel operations. Banking AI use cases include automated threat intelligence and prevention systems, fraud analysis and investigation, and program advisors and recommendation systems. Discrete manufacturing AI use cases including automated preventative maintenance, quality management investigation and recommendation systems. Improved diagnosis and treatment systems are a key focus in healthcare.
In this April 2018 report, McKinsey highlights numerous use cases concluding that ”AI can most often be adopted and create value where other analytics methods and techniques are also creating value”. McKinsey emphasis that “abundant volumes of rich data from images, audio, and video, and large-scale text are the essential starting point and lifeblood of creating value with AI”. McKinsey’s AI focus in the report is particularly in relation to deep learning techniques such as feed forward neural networks, recurrent neural networks, and convolutional neural networks.
Examples highlighted by McKinsey include a European trucking company who reduced fuel costs by 15 percent by using AI to optimize routing of delivery traffic, an airline who uses AI to predict congestion and weather-related problems to avoid costly cancellations, and a travel company who increase ancillary revenue by 10-15% using a recommender system algorithm trained on product and customer data to offer additional services. Other specific areas highlighted by McKinsey are captured in the following paragraph:
“AI’s ability to conduct preventive maintenance and field force scheduling, as well as optimizing production and assembly processes, means that it also has considerable application possibilities and value potential across sectors including advanced electronics and semiconductors, automotive and assembly, chemicals, basic materials, transportation and logistics, oil and gas, pharmaceuticals and medical products, aerospace and defense, agriculture, and consumer packaged goods. In advanced electronics and semiconductors, for example, harnessing data to adjust production and supply-chain operations can minimize spending on utilities and raw materials, cutting overall production costs by 5 to 10 percent in our use cases.”
McKinsey calculated the value potential of AI from neural networks across numerous sectors, as per the graph below, amounting to $3.5 to $5.8 trillion. Value potential is defined as both in the form of increased profits for companies and lower prices or higher quality products and services captured by customers, based off the 2016 global economy. They did not estimate the value potential of creating entirely new product or service categories, such as autonomous driving.
click to enlarge
McKinsey identified several challenges and limitations with applying AI techniques, as follows:
- Making an effective use of neural networks requires labelled training data sets and therefore data quality is a key issue. Ironically, machine learning often requires large amounts of manual effort in “teaching” machines to learn. The experience of Microsoft with their chatter bot Tay in 2016 illustrates the shortcoming of learning from bad data!
- Obtaining data sets that are sufficiently large and comprehensive to be used for comprehensive training is also an issue. According to the authors of the book “Deep Learning”, a supervised deep-learning algorithm will generally achieve acceptable performance with around 5,000 labelled examples per category and will match or exceed human level performance when trained with a data set containing at least 10 million labelled examples.
- Explaining the results from large and complex models in terms of existing practices and regulatory frameworks is another issue. Product certifications in health care, automotive, chemicals, aerospace industries and regulations in the financial services sector can be an obstacle if processes and outcomes are not clearly explainable and auditable. Some nascent approaches to increasing model transparency, including local-interpretable-model-agnostic explanations (LIME), may help resolve this explanation challenge.
- AI models continue to have difficulties in carrying their experiences from one set of circumstances to another, applying a generalisation to learning. That means companies must commit resources to train new models for similar use cases. Transfer learning, in which an AI model is trained to accomplish a certain task and then quickly applies that learning to a similar but distinct activity, is one area of focus in response to this issue.
- Finally, one area that has been the subject of focus is the risk of bias in data and algorithms. As bias is part of the human condition, it is engrained in our behaviour and historical data. This article in the New Scientist highlights five examples.
In 2016, Accenture estimated that US GDP could be $8.3 trillion higher in 2035 because of AI, doubling growth rates largely due to AI induced productivity gains. More recently in February this year, PwC published a report on an extensive macro-economic impact of AI and projected a baseline scenario that global GDP will be 14% higher due to AI, with the US and China benefiting the most. Using a Spatial Computable General Equilibrium Model (SCGE) of the global economy, PwC quantifies the total economic impact (as measured by GDP) of AI on the global economy via both productivity gains and consumption-side product enhancements over the period 2017-2030. The impact on the seven regions modelled by 2030 can be seen below.
click to enlarge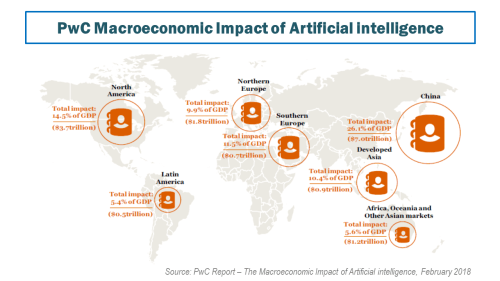
PwC estimates that the economic impact of AI will be driven by productivity gains from businesses automating processes as well as augmenting their existing labour force with AI technologies (assisted, autonomous and augmented intelligence) and by increased consumer demand resulting from the availability of personalised and/or higher-quality AI-enhanced products and services.
In terms of sectors, PwC estimate the services industry that encompasses health, education, public services and recreation stands to gain the most, with retail and wholesale trade as well as accommodation and food services also expected to see a large boost. Transport and logistics as well as financial and professional services will also see significant but smaller GDP gains by 2030 because of AI although they estimate that the financial service sector gains relatively quickly in the short term. Unsurprisingly, PwC finds that capital intensive industries have the greatest productivity gains from AI uptake and specifically highlight the Technology, Media and Telecommunications (TMT) sector as having substantial marginal productivity gains from uptaking replacement and augmenting AI. The sectoral gains estimated by PwC by 2030 are shown below.
click to enlarge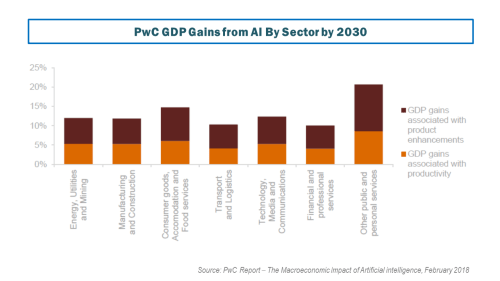
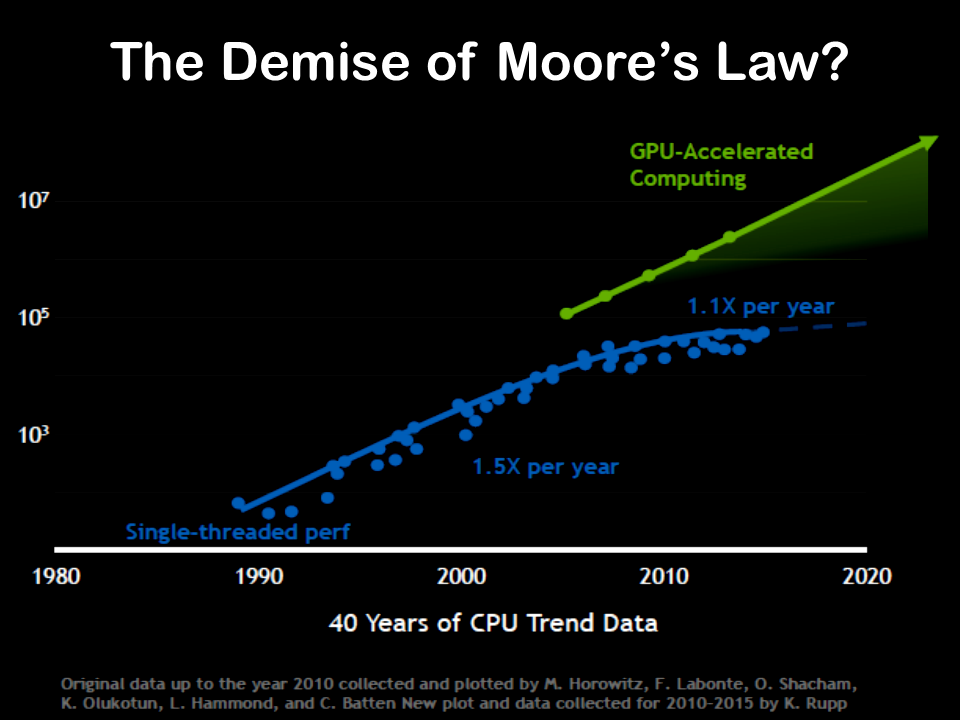
A key element of these new processes is the computing capabilities needed to process so much data that underlies AI. This recent article in the FT highlighted how the postulated demise of Moore’s law after its 50-year run is impacting the micro-chip sector. Mike Mayberry of Intel commented that “the future is more heterogeneous” when referring to the need for the chip industry to optimise chip design for specific tasks. DARPA, the US defence department’s research arm, has allocated $1.5 billion in research grants on the chips of the future, such as chip architectures that combine both power and flexibility using reprogrammable “software-defined hardware”. This increase in focus from the US is a direct counter against China’s plans to develop its intellectual and technical abilities in semiconductors over the coming years beyond simple manufacturing.
One of the current leaders in specialised chip design is Nvidia (NVDA) who developed software lead chips for video cards in the gaming sector through their graphics processing unit (GPU). The GPU accelerates applications running on standard central processing units (CPU) by offloading some of the compute-intensive and time-consuming portions of the code whilst the rest of the application still runs on the CPU. The chips developed by NVDA for gamers have proven ideal in handling the huge volumes of data needed to train deep learning systems that are used in AI. The exhibit below from NVDA illustrates how they assert that new processes such as GPU can overcome the slowdown in capability from the density limitation of Moore’s Law.
click to enlarge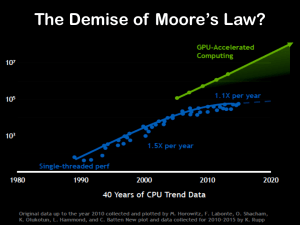
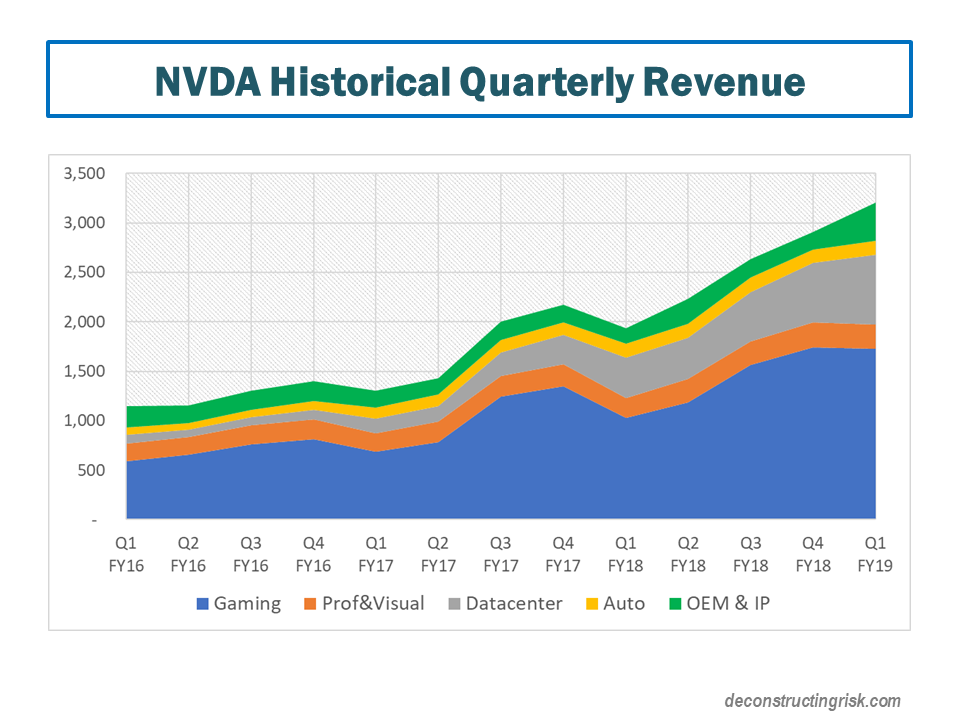
NVDA, whose stock is up over 400% in the past 24 months, has been a darling of the stock market in recent years and reported strong financial figures for their quarter to end April, as shown below. Their quarterly figures to the end of July are eagerly expected next month. NVDA has been range bound in recent months, with the trade war often cited as a concern with their products sold approximately 20%, 20%, and 30% into supply chains in China, other Asia Pacific countries, and Taiwan respectively
click to enlarge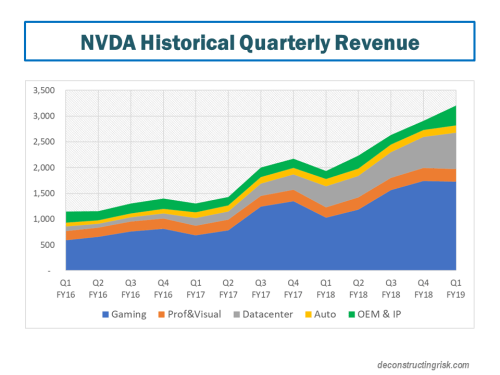
Although seen as the current leader, NVDA is not alone in this space. AMD recently reported strong Q1 2018 results, with revenues up 40%, and has a range of specialised chip designs to compete in the datacentre, auto, and machine learning sectors. AMD’s improved results also reduce risk on their balance sheet with leverage decreasing from 4.6X to 3.4X and projected to decline further. AMD’s stock is up approximately 70% year to date. AMD’s 7-nanonmeter product launch planned for later this year also compares favourably against Intel’s delayed release date to 2019 for its 10-nanometer chips.
Intel has historically rolled out a new generation of computer chips every two years, enabling chips that were consistently more powerful than their predecessors even as the cost of that computing power fell. But as Intel has run up against the limits of physics, they have reverted to making upgrades to its aging 14nm processor node, which they say performs 70% better than when initially released four years ago. Despite advances by NVDA and AMD in data centres, Intel chips still dominate. In relation to the AI market, Intel is focused on an approach called field-programmable gate array (FPGA) which is an integrated circuit designed to be configured by a customer or a designer after manufacturing. This approach of domain-specific architectures is seen as an important trend in the sector for the future.
Another interesting development is Google (GOOG) recently reported move to commercially sell, through its cloud-computing service, its own big-data chip design that it has been using internally for some time. Known as a tensor processing unit (TPU), the chip was specifically developed by GOOG for neural network machine learning and is an AI accelerator application-specific integrated circuit (ASIC). For example, in Google photos an individual TPU can process over 100 million photos a day. What GOOG will do with this technology will be an interesting development to watch.
Given the need for access to large labelled data sets and significant computing infrastructure, the large internet firms like Google, Facebook (FB), Microsoft (MSFT), Amazon (AMZN) and Chinese firms like Baidu (BIDU) and Tencent (TCEHY) are natural leaders in using and commercialising AI. Other firms highlighted by analysts as riding the AI wave include Xilinx (XLNX), a developer of high-performance FPGAs, and Yext (YEXT), who specialise in managing digital information relevant to specific brands, and Twilio (TWLO), a specialist invoice and text communication analysis. YEXT and TWLO are loss making. All of these stocks, possibly excluding the Chinese ones, are trading at lofty valuations. If the current wobbles on the stock market do lead to a significant fall in technology valuations, the stocks on my watchlist will be NVDA, BIDU and GOOG. I’d ignore the one trick ponys, particularly the loss making ones! Specifically, Google is one I have been trying to get in for years at a sensible value and I will watch NVDA’s results next month with keen interest as they have consistently broken estimates in recent quarters. Now, if only the market would fall from its current heights to allow for a sensible entry point…….maybe enabled by algorithmic trading or a massive trend move by the passives!