Before I unleash my musings on the latest Centurylink (CTL) results, building on this recent CTL post, I will touch on some industry trends and some CTL specific items that are relevant in my opinion. As regular readers will know, the increased use of artificial intelligence (AI) by businesses, particularly in business processes, is an area that fascinates me (as per this post). How such process improvements will change a capital- and labour-intensive sector such as telecom (as per this post) is one of the reasons I see such potential for CTL.
Whilst reading some recent articles on digital developments (such as this and this and this), I cannot but be struck by the expanded networking needs of this future. All this vast amount of new data will have to be crunched by machines, likely in data centres, and updated constantly by real time data from the field. Networks in this era (see this post on 5G) will need to be highly efficient, fluid and scalable, and have a deep reach. Very different from the fixed cost dumb pipe telecoms of old!
CTL have outlined their ambition to be such a network provider and are undertaking a digital transformation programme of their business to achieve that goal. CEO Jeff Storey has gone as far as saying that CTL “is not a telecom company, but that we are a technology company”. Time will tell on that one!
Today, industry trends from business telecom revenues (i.e. enterprises from SME to global giants plus wholesale business) are flat to declining, as highlighted in this post. Deciphering recent trends has not been made any easier by the introduction of the new revenue recognition accounting standard ASC606. Where possible, the updated graph below shows revenues under the new standard from Q1 2018.
click to enlarge
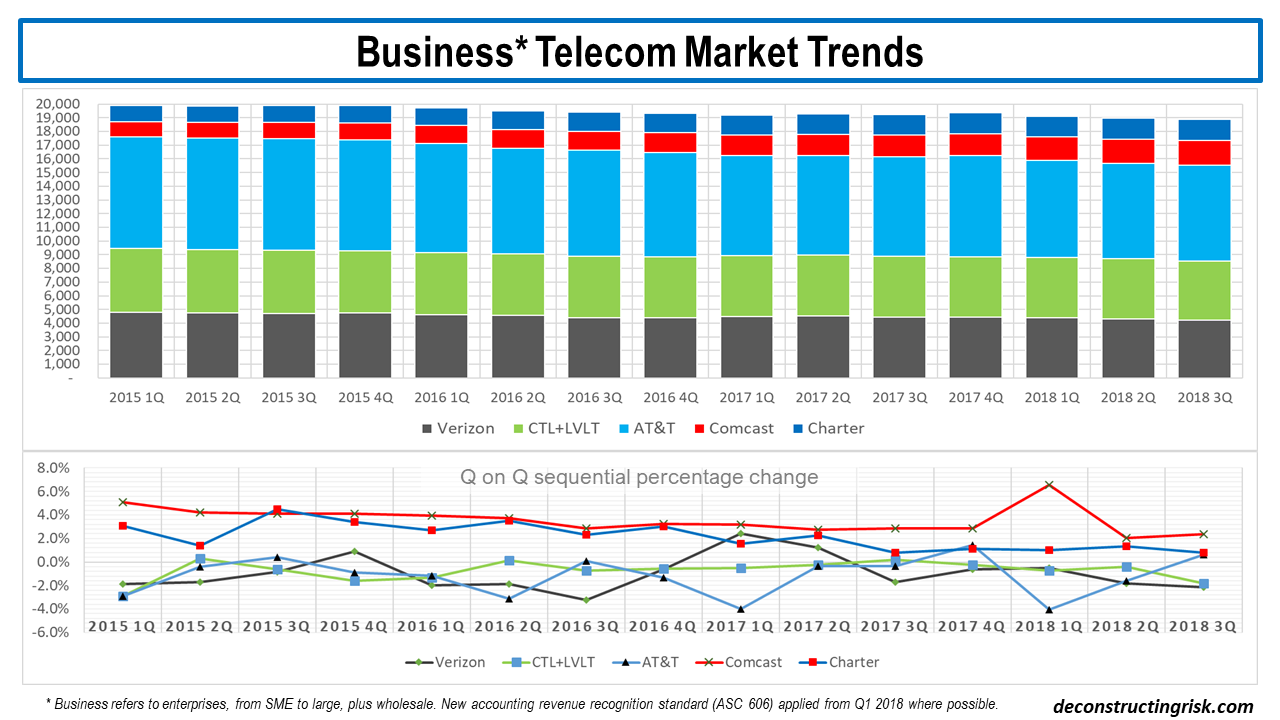
This data shows an estimated annual decline in overall annual revenues for 2018 of 1.5%, compared to 1.2% in 2017 and 2% for each of the preceding 2 years. Over the past 8 quarters, that’s about a 33-basis point sequential quarterly drop on average. Different firms are showing differing impacts from the accounting change on their business revenue. Comcast showed a 6.5% jump in Q1 2018 before returning to trend whilst AT&T showed a 4% drop in Q1 2018 before returning to more normal quarterly changes. Rather than trying to dismantle the impact of the accounting change, its easier to simply accept the change as its obvious the underlying trends remain, as the bottom graph above illustrates. Whilst accepting these 5 firms do not make up all the US, let alone the global, telecom market, some interesting statistics from this data are shown below.
click to enlarge
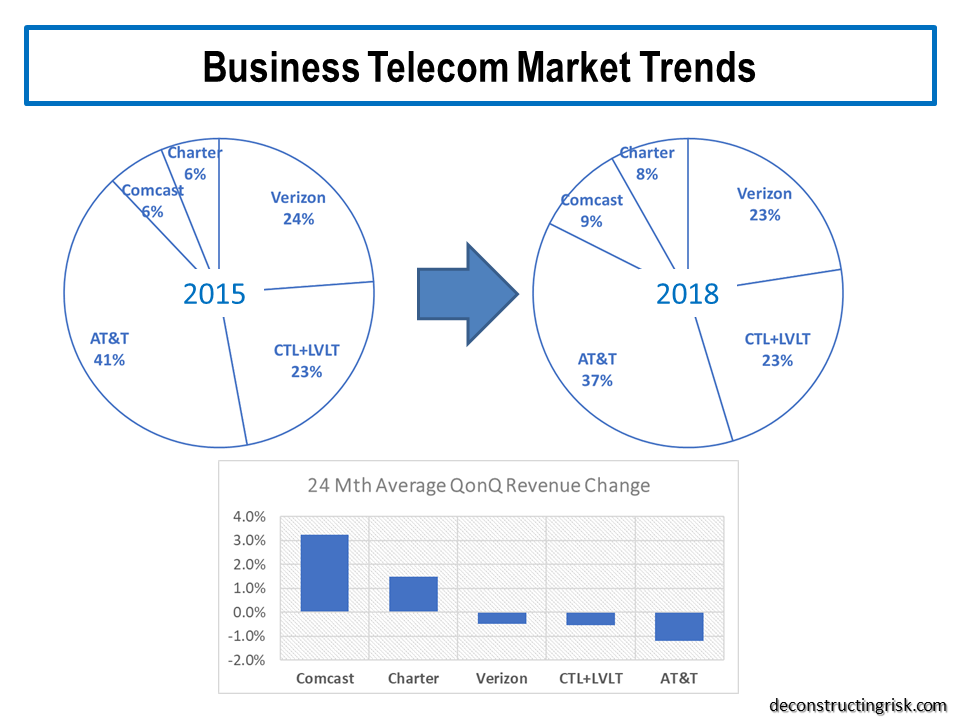
Although the accounting change has likely skewed figures in the short term, the exhibit above shows that AT&T is losing market share whilst the cable firms are growing their business revenues albeit from lower bases than the big players. Verizon and the new CTL have performed slightly below market trends (i.e. 50 basis point average quarterly sequential declines versus overall at 33 basis points).
Before I get onto CTL’s Q3 results, this article from Light Reading illustrates some of the changes underway at the firm to transform its business. The changes are centred around 4 themes – increasing network visibility, delivering business-owned automation, encouraging a lean mindset, and skills transformation.
On network viability, CTL is layering federation tools on top of its existing systems. Federated architecture (FA) is a pattern in enterprise architecture that allows interoperability and information sharing between semi-autonomous de-centrally organized lines of business, information technology systems and applications. The initial phase of this federation was with customer and sales systems such as those used for quoting, order entry, order status, inventory management and ticketing. The goal is to move towards a common sales ecosystem and standard portals that automate customer’s journeys from order to activation and beyond. A common narrative of CTL’s transformation is to give customers the tools to manage their networking capabilities like they do using the cloud. This is more of a network as a service or network on demand that CTL say is the future for telecom providers. This interview with the newly appointed CTO of CTL gives further insight into what the firm is doing in this on demand area, including changes underway to meet the increased SD-WAN demand and the upcoming deluge of data in the 5G era.
Business owned automation is allowing different business units to own their own automation projects, whilst been supported by centralised centres of excellence in areas such as robotic process automation (RPA), digital collaboration, mobility and analytics. Training is provided by the centralised units. Empowering the business units encourages a key cultural change in adopting a lean mindset across the firm. Ensuring that people in the firm are retrained and motivated is a core part of CTL’s plans as change only comes from within and as the firm continues to downsize (they have already reduced headcount by 12%) its important that staff morale and skills transformation is a focus as the business changes.
So, moving on to CTL’s Q3 results. The market has not reacted well to the Q on Q drop of 3.6% in revenues, with weakness seen across all business segments, and the stock is trading down around $19 as a result. The trends highlighted above have been exasperated by CTL dropping or renegotiating lower margin business such as contracts involving customer premises equipment (so called CPE). Of the $80 million quarterly revenue drop (under ASC606) in Q3, $30 million was attributed to the culling of low margin business. The remaining $50 million drop is about twice the average drop in recent times, thereby raising analyst concerns about an increase in trend revenue declines.
However, there are two points to note here. Firstly, using revenue figures before the application of ASC606, the net drop was more in line at $37 million (i.e. $67-$30) and comparable with the Q2 non-ASC606 drop of $40 million. Secondly, and more importantly, the trend is lumpy and given CTL’s transformation focus, it makes total sense to me for CTL to cull low margin non-network centric revenues. Management were explicit in stating their intention “to focus on the network-centric things” and that this business is “distracting our organization and it’s not giving us anything, so we’ll stop it”. To me, that demonstrates confidence in the direction of the business. As Storey emphasised, when referring to culling low margin business, “we manage this business for free cash flow, free cash flow per share, these are good things to be doing”.
Analysts concern that cutting expenses longer term cannot be a sustainable business plan without revenue growth at some point is certainly valid (and is one of the key risks with CTL). Indeed, I estimate that there is about $900 million and $500 million of quarterly legacy business and consumer revenues respectively (about 15% and 10% of total quarterly revenues) that could fall off at an accelerated pace as CTL refocuses the business over the medium term. CTL’s return to top line growth could be several years off yet. More on this later.
Another area of concern from analysts was the fact that CTL will spend approx. $500 million less on capex in 2018 compared to original projections (with levels projected to return to a more normal 16% of revenues for 2019 and beyond). This could be interrupted as a desire not to invest in the business to inflate free cash-flow, never a good sign for any company. However, again management explained this as a desire to refocus capital spending away from items like copper upgrades and towards strategic areas. They cited the approval to bring on-net another 7,000 to 8,000 buildings and the use of strategic targeting of capex (using AI) across consumer and business geographies to maximise returns in urban areas where 5G infrastructure will be needed in the future. Again, a more disciplined approach to capex makes total sense to me and demonstrates the discipline this management team is imposing on the business.
What seems to have been missed in the reaction to Q3 results is the extraordinary progress they have made on margin improvements. The EBITDA margin again grew to 39.3% with the projected operational synergies of $850 million now targeted to be achieved by year end. Management are keen to move the focus from integration to digital transformation from 2019. Achieving the targeted operational synergies so soon, particularly when we know that network expense synergies do not come through until 2 to 3 years after a merger, is an amazing achievement. It also highlights that their projected cost synergies of $850 million were way way under-baked. As I highlighted in this recent CTL post, I suspected this under-baking was to protect against the risk of any further acceleration in the underling margin erosion at the old CTL business as legacy business declined.
CTL’s discipline in extracting costs, as seen by actions such as the (painful) 12% headcount reduction, is central to my confidence in CTL’s management achieving their strategic aims. I do not believe that a further $250 million and $200 million of cost synergies in 2019 and 2020 respectfully through further synergies, network grooming efforts and the digital transformation initiative is unreasonable. That would bring overall cost synergies to $1.3 billion, a level consistent to what LVLT achieved in the TWTC merger.
So, given the likelihood of an increased purposeful erosion in low margin legacy business over the next several years combined with a higher level of cost extraction, I have recalculated my base and pessimistic scenarios from my previous post.
My base scenario, as per the graph below, shows annual revenues effectively flatlining over the next 3 years (2019 to 2021) around $23.3 to $23.6 billion before returning to modest top-line growth thereafter (i.e. between 1% and 1.5% annual growth) with an EBITDA margin of 42% achieved by the end of 2021 and maintained thereafter. This revenue profile mirrors that of previous LVLT mergers, albeit a longer period of flatlining revenues due to the amount of old legacy CTL to burn off. Capex is assumed at 16% of revenue from 2019 onwards. My projections also include further interest rate increases in 2019 and 2020 (as a reminder every 25-basis point change in interest rate results in an 8.5 basis point change in CTL’s blended rate). The current dividend rate is maintained throughout with FCF coverage ratio reducing from the low 70’s in 2019 to around 60% by the end of 2021. My DCF valuation for CTL under these base projections is $23 per share. That’s about 20% above its current level around $19 plus a 11% dividend yield.
click to enlarge

My pessimistic scenario, as per the graph below, assumes that the hoped-for revival of CTL into an on-demand service provider in the 5G age does not result in revenue growth after the legacy business has eroded for whatever reason (other technological advances over the need for a deep fiber network optic been the most likely). Annual revenue continues to decline to below $22 billion by 2021 and does not get above that level again until 2025. Although this scenario would be extreme, its not unknown in the telecom industry for future jumps in data traffic to result in falling revenues (eh, remember the telecom winter!). EBITDA margin levels get to 41% by the end of 2021 and slowly rise to 41.5% thereafter on further cost cutting. Capex and interest rate assumptions are as per the base scenario.
click to enlarge
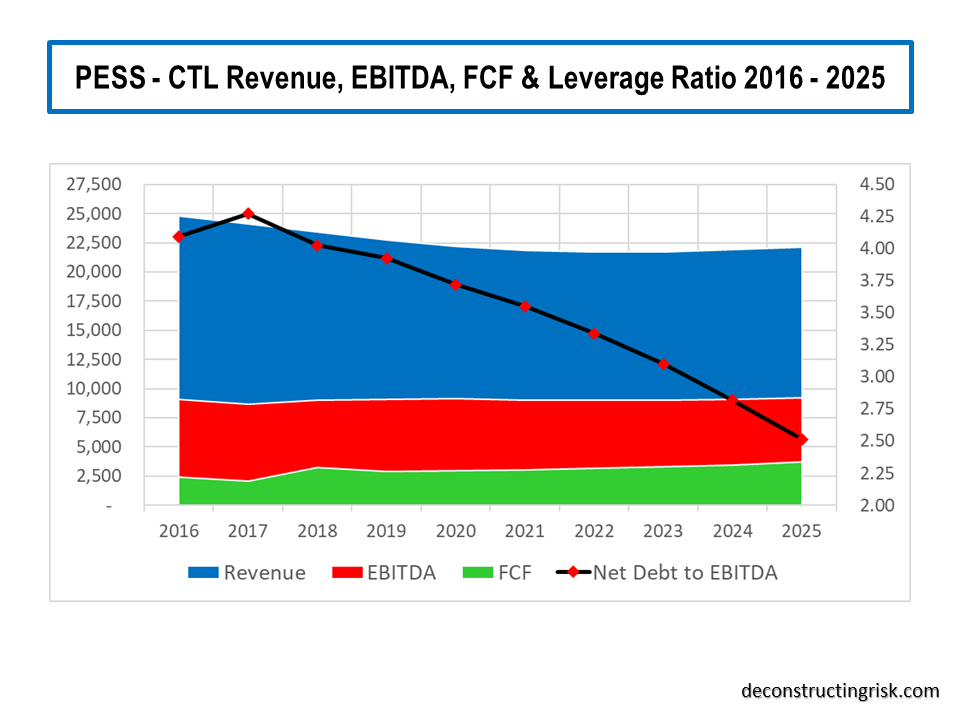
In the pessimistic scenario the dividend level of $2.16 per share must be cut by 50% from 2020 to reflect the new reality and to deleverage the balance sheet. Although the share price would likely suffer greatly in such a scenario, my DCF valuation is $14 per share, 26% below the current $19 share price, not forgetting the reduced dividend yield after the 50% cut.
As per my previous post on CTL, I see little point in contemplating an optimistic scenario until such time as revenue trends are clearer. A buy-out at a juicy premium is the most likely upside case.
Consideration should be given in any projections over the medium term on the impact and timing of the next recession which is certain to happen over the 2019 to 2025 period. Jeff Storey has argued in the past that recession is good for firms like CTL as enterprises look to save money through switching from legacy services to more efficient on demand services. Although there is an element of truth to this argument, the next recession will likely put further pressures on CTL’s top-line (alternatively, an outbreak of inflation may help pricing pressures!!). Higher interest rates and lower multiples are a risk to the valuation of firms like CTL and the uncertainty over the future macro-economic environment make CTL a risky investment. Notwithstanding the inevitability of a recession at some time, I do feel that the revenue projections above are already conservative given the explosion in network demand that is likely over the next decade, although increased signs of recession in late 2019 or 2020 would temper my risk appetite on CTL.
To me, one of the biggest risks to CTL is the CEO’s health. Given Sunit Patel has left for T-Mobile (who I hope may be a potential buyer of CTL after they get the Sprint deal embedded and/or abandoned) and the new CFO will take some time to get accepted in the role, any potential for CTL not to have Jeff Storey at the helm over the next 2 years would be very damaging. Identifying and publicly promoting a successor to Jeff Storey is something the Board should be actively considering in their contingency planning.
For now, though, I am reasonably comfortable with the risk reward profile on CTL here, absent any significant slow down in the US economy.